Products
Industry Knowledge
Posted on:
May 27, 2026Why analytics workloads don't belong on your PLC

7 minute read
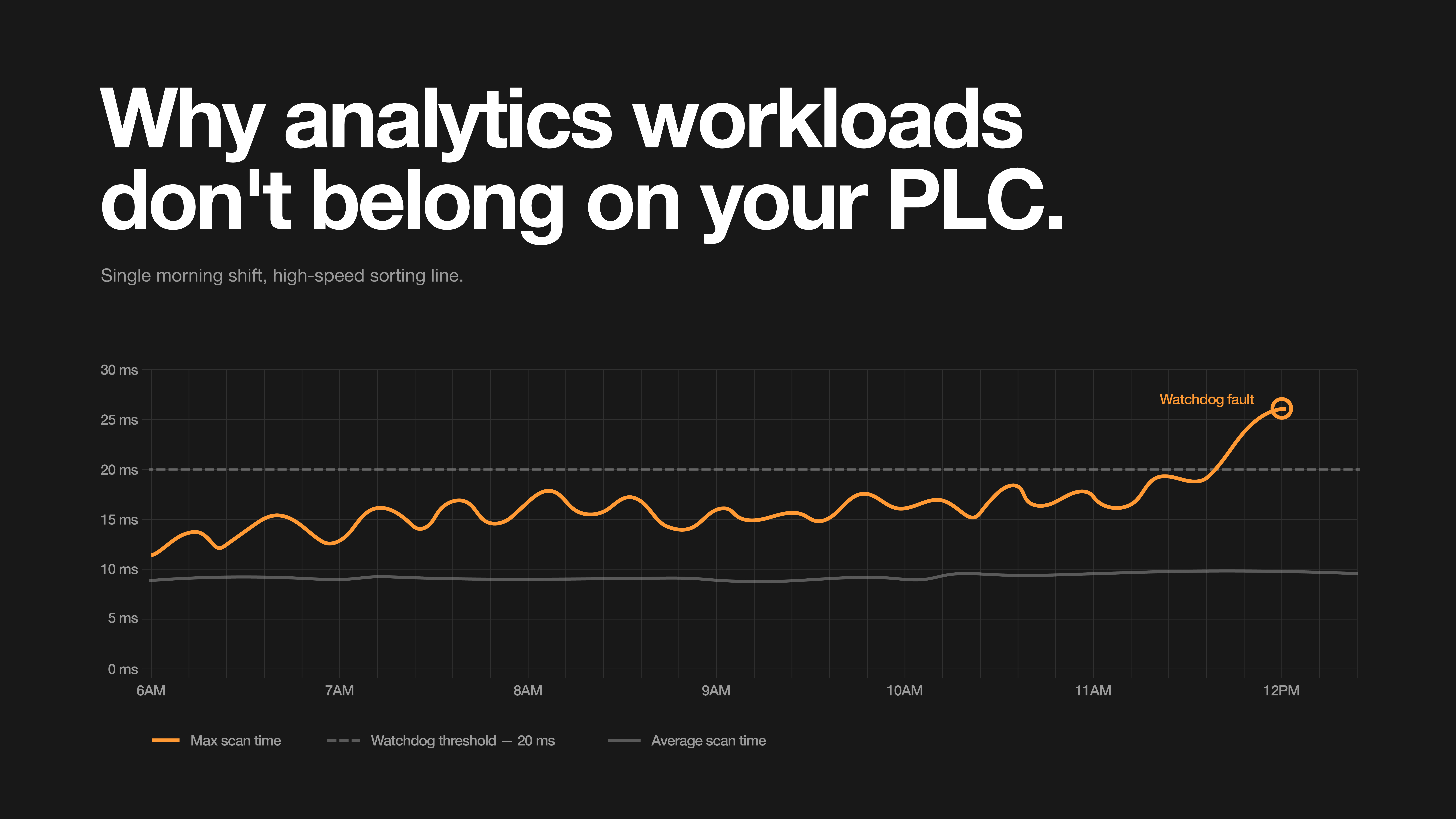
A high-speed sorting line started missing reject gates on Tuesday mornings. The integrator had added a buffering and trending routine to the main PLC eighteen months earlier to feed a homegrown dashboard. The logic was clean. The scan time wasn't. Average scan crept from 8 ms to 14 ms, then started spiking past 25 ms during the morning shift when the data load was heaviest. The diverter logic depended on photo-eye state at the moment the package crossed a fixed encoder count. Most cycles, the timing still worked. Some cycles, the scan was late enough that the package was past the gate before the output updated. Max scan eventually crossed the watchdog threshold and the PLC faulted. The fix wasn't better math. The fix was moving the math somewhere else.
That story is familiar to anyone who has spent a few years on a plant floor. It's the kind of failure that doesn't show up until someone goes looking at the max scan history.
The determinism distinction

A PLC is built around one promise: the scan cycle finishes on time, every time. Read inputs, solve logic, write outputs, repeat. Typical cycles for machine control land between 1 and 50 ms depending on platform and program size. Process control tolerates 50 to 100 ms. High-speed packaging and sorting push the budget under 2 ms.
High-performance motion is its own conversation. Servo current loops close on the drive itself at 16 to 50 kHz. Position and velocity loops typically run from 100 Hz to 20 kHz, either on a dedicated motion controller, a motion coprocessor in the PLC chassis, or integrated into the drive. The main PLC scan coordinates motion at the machine-control rate. It rarely closes the servo loop directly anymore.
What makes a PLC trustworthy for control is not raw speed. It's consistency. Jitter, the variation in when a task actually starts and how long it takes to complete, matters more than average scan time. A 10 ms task that usually finishes in 10 ms but occasionally stretches to 14 ms is showing jitter. Interlocks, I/O scanning, encoder-based event detection, and any logic that depends on consistent timing all degrade when jitter grows. Average scan time can stay healthy while the maximum drifts upward, which is exactly what makes the failure mode hard to catch.
Edge compute is non-deterministic by design. An industrial PC running a historian, a vision model, or an analytics workload is built for throughput and compute density, not consistent timing. The OS schedules tasks. Garbage collection runs when it runs. A query against a time-series database might return in 4 ms or 400 ms depending on what else is happening on the box. That's fine, because nothing on the line is waiting on the answer to decide whether to open a valve.
Mixing those two design philosophies on the same processor is where things go wrong. Analytics code on a control CPU steals scan time. Worse, it steals it unpredictably.
What belongs where
The split is cleaner than the marketing around it suggests.
Control layer. Interlocks. Sequencing and coordination between machines. I/O scanning. Alarm logic that must always be active even if every other system on the plant network is down. PID loops on critical processes. Threshold-based monitoring for vibration trips, temperature alarms, current limits, anything that needs to respond now. Anything where the question being answered is "what should happen next, right now." If a late answer means a scrapped part, a damaged tool, or a hurt operator, it belongs on the PLC.
Edge layer. Predictive maintenance models. Long-window FFT and spectral analysis. Historian queries and long-horizon trending. Condition monitoring aggregated across multiple assets. OEE and downtime calculations. Vision inference for quality inspection. Energy analytics. Machine learning of any meaningful complexity. Anything that aggregates data over time to answer "why is this happening" or "what is likely to happen next week." The latency budget is generous, and the workload benefits from compute and memory that a PLC was never designed to provide.
Modern PLCs can technically do some of these things. A controller with the headroom to run a small FFT block on a single vibration channel will run it just fine, and some platforms offer this as a packaged function. The question is not whether the PLC can do it on the day you write it. The question is what happens when the workload grows, when a second channel is added, when someone wants a longer FFT window, when the trending logic accumulates. Once the analytics workload starts competing with control logic for scan time, the architecture has already gone wrong. The earlier the split, the cleaner.
One clarification worth making, because it trips up the conversation often. Running a soft PLC runtime on an industrial PC is not the same as putting control logic at the edge. CODESYS, TwinCAT, or a vendor soft runtime is still a deterministic control engine. A properly configured TwinCAT installation with isolated CPU cores can hit cycle times in the low hundreds of microseconds with sub-microsecond jitter, depending on hardware and program. The line that matters is between control runtime and analytics runtime. It is not between PLC chassis and PC chassis. Putting an MQTT publisher and a historian buffer inside the PLC program is the problem. Running a soft PLC on an IPC next to an HMI is not.
The architecture pattern
The standard pattern in 2026 looks like this. PLC at the bottom, handling control. An edge node directly adjacent to it, usually an industrial PC or panel PC running a historian, a vision inference engine, an MQTT broker, or condition monitoring. Data flows from the PLC to the edge node over the protocol the PLC speaks natively. Newer PLCs increasingly expose OPC UA directly. Legacy and many midrange PLCs publish over Modbus TCP, EtherNet/IP, Siemens S7, or a vendor-native protocol. The edge node contextualizes the data and republishes it onto a unified namespace, typically over MQTT Sparkplug B. Plant systems, MES, and cloud analytics subscribe to that namespace. Commands rarely flow the other way. When they do, they pass through the PLC's normal logic rather than bypassing it.
The emerging consensus is layered intelligence. Smaller models close to the asset for fast local response. Larger models at the edge gateway for line-wide context. Heavier analytics in plant systems or cloud for fleet-level patterns. The controller tells you about the system. The edge gateway tells you about the whole line.
The layered architecture itself is not new. The ISA-95 automation pyramid has been in the standard since the 1990s, and the underlying CIM model traces back to the 1970s. What is newer is the explicit edge layer sitting next to the PLC, dedicated to analytics and protocol translation. That pattern took hold roughly a decade ago, when industrial PCs became cheap enough to deploy one per cell rather than one per plant. Before that, the economics pushed analytics onto whatever compute was already in the cabinet, which usually meant the PLC. That was a defensible tradeoff when edge hardware was expensive. It is not anymore.
The test
If the analytics workload disappeared tomorrow, would the line still run?
If yes, the architecture is right. The analytics live somewhere they can be updated, restarted, debugged, or removed without anyone on the floor noticing.
If no, control logic has ended up somewhere it doesn't belong, and the maximum scan time on the controller is the only thing standing between you and a watchdog fault.